我们下面来讲一讲如何理解递归:
现在请大家回到本文的开头继续阅读。(除非你读了3遍以上)
是不是一头雾水?但实际上这就是一个递归的过程。
如果你还是不懂,那么让我们看看Google是如何解释递归的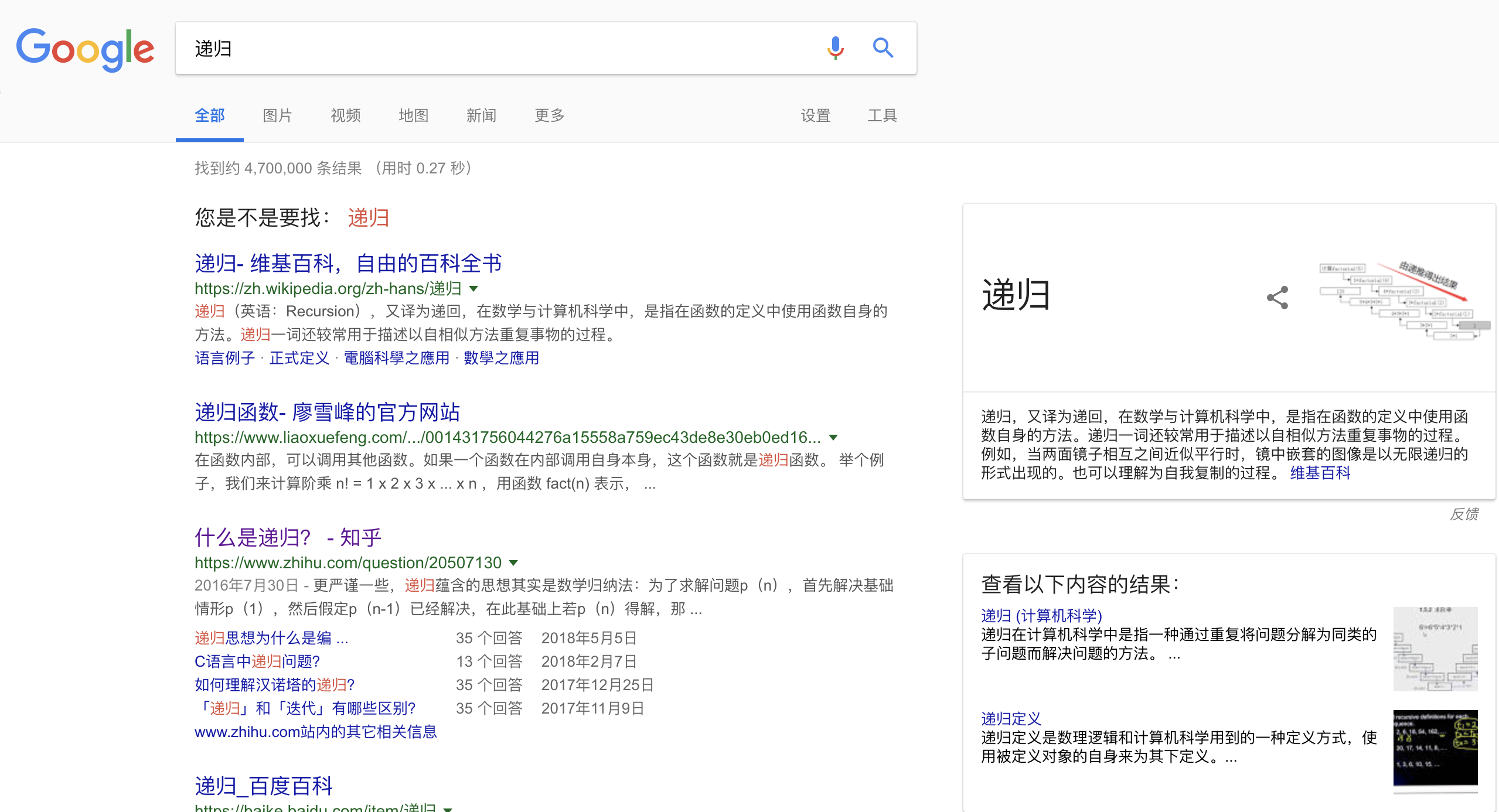
“您是不是要找:递归”
“您是不是要找:递归”
...
这个循环将无限制的进行下去
再在程序代码的角度描述一下
int f(int x) {
if(x == 3) return 1;
return f(x+1);
}通过这三个例子你是否可以体会到递归的思想了呢?
> 递归(Recursion)在计算机科学中是指一种通过重复将问题分解为同类的子问题而解决问题的方法。[1] 递归式方法可以被用于解决很多的计算机科学问题,因此它是计算机科学中十分重要的一个概念。[2] 绝大多数编程语言支持函数的自调用,在这些语言中函数可以通过调用自身来进行递归。计算理论可以证明递归的作用可以完全取代循环,因此有很多在函数编程语言(如Scheme)中用递归来取代循环的例子。 >计算机科学家尼克劳斯·维尔特如此描述递归: > > 递归的强大之处在于它允许用户用有限的语句描述无限的对象。因此,在计算机科学中,递归可以被用来描述无限步的运算,尽管描述运算的程序是有限的。 > ——尼克劳斯·维尔特[3] 以上是维基百科对递归的定义,但实际上我们可以这样粗暴的去理解它: 递归就是函数在调用自身 当然这个说法十分之不严谨,但也不妨碍我们去理解程序设计中的“递归”。 我们拿出前面举的例子的第三个来详细讲解 ```cpp int f(int x) { if(x == 3) return 1; return f(x+1); } ``` 请大家想一想,这如果我调用f(1),函数会返回什么? f(2)呢?f(3)、f(4)呢? 其实,当变量x小于等于3的时候我们返回的都是1,而超过了3将会让函数无限调用自身,也就是无限递归。 那么为什么会是这样呢?我们可以这么想,当调用f(1)的时候,f(x)函数会返回f(x+1)的值也就是f(2)的值,而在计算出f(2)的值之前,我们又得算出f(3)的值,前两个值得靠后面的计算才能得出。这也就是我们的递推过程。 那么到了f(3)情况就有所不同了,f(3)的值已经被定义为了1,那么在这里,f(2)的值也自然而言就计算出来了——也是1,同理,最后我们可以得出f(1)的值也就是1。这也就是我们所说的回归过程。 所谓递归也就是也就是这两个过程。 那么为什么f(4)会导致无限递归呢? 我们要看函数内那唯一一个条件语句,它就是这个递归函数的递归边界,也就是说,当变量x等于3的时候,这个函数将结束递推过程,返回我们已经设置好的值,并开始回归过程。 由于这个递归边界的定义,注定了在x大于等于4的时候会引发无限递归,所以我们在定义递归边界的时候需要注意。 在C语言中,由于存在调用栈(请读者自行拓展),语言本身支持函数自身调用自身,也就可以实现递归结构了。 ## 拓展与思考: * 尾递归是什么?尾递归如何改循环? * 栈空间是什么?递归真的可以无限进行下去吗?
参考资料:https://zh.wikipedia.org/zh-hans/%E9%80%92%E5%BD%92
