最近正在做一个炼丹深度学习的项目,不可避免地使用到了GPU加速。其中,在使用cuDNN的时候遇到了CUDNN_STATUS_ALLOC_FAILED的问题,记录一下。
首先给出我的系统硬件以及软件环境:
- OS: Windows Server 2019 Standard
- CPU: Intel Xeon W-2123 3.6GHz
- Memory: 64G ECC
- GPU: NVIDIA Quadro P4000(8G)
- Tensorflow: 1.13.2
- Keras: 2.1.5
- CUDA: 10.0
- cuDNN: 7.3
具体报错信息如下:
1
2
3
4
5
6
7
8
9
10
11
12
| 2021-03-22 20:39:27.884555: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
2021-03-22 20:39:27.888005: E tensorflow/stream_executor/cuda/cuda_dnn.cc:334] Could not create cudnn handle: CUDNN_STATUS_ALLOC_FAILED
Traceback (most recent call last):
File "C:\ProgramData\Anaconda3\envs\ly\lib\site-packages\tensorflow\python\client\session.py", line 1334, in _do_call
return fn(*args)
File "C:\ProgramData\Anaconda3\envs\ly\lib\site-packages\tensorflow\python\client\session.py", line 1319, in _run_fn
options, feed_dict, fetch_list, target_list, run_metadata)
File "C:\ProgramData\Anaconda3\envs\ly\lib\site-packages\tensorflow\python\client\session.py", line 1407, in _call_tf_sessionrun
run_metadata)
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.
[[{{node conv2d_1/convolution}}]]
[[{{node concat_9}}]]
|
Quick Fix
此处参考stackoverflow上的一个方案。
1
2
| import os
os.environ["CUDA_VISIBLE_DEVICES"] = "-1"
|
直接禁用GPU,自然也就不会牵扯到cuDNN。
Problem solved, amazing!
个鬼。
禁用GPU也就意味着禁用了GPU加速,意味着可怜的CPU要burn itself,这在对于效率有要求的生产环境是不行的🙅♂️。
观察
在建立模型后显存直接爆炸,如下图:
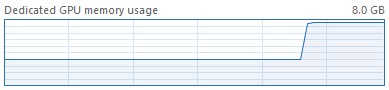
查阅资料,初步猜测是显存不足导致的,所以想到了限制一下显存的消耗:
1
2
3
4
5
| import tensorflow as tf
from keras.backend.tensorflow_backend import set_session
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
set_session(tf.Session(config=config))
|
限制后显存明显降低了。
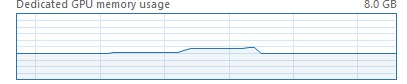
但是崩溃的问题依旧😓。
又想到了一个问题,因为服务器是多个项目组共用的,是不是有可能为其它组正在使用导致cuDNN无法创建句柄呢?
有可能,但是我也不能去关别人的程序呀boss不得打死我😅。
疑问留在这里,等服务器空了就来补充。(当然可能我也压根不会填坑,不如留给读者当一个思路)
Reference