续接上一篇文章,我们继续来讨论时间复杂度的应用。
---
首先我们应该明确一点,时间复杂度数量级大的算法运行时间不一定要比小的运行时间要来的长,相反,可能相去甚远。
原因其实可很简单——影响程序运行时间的因素有很多。
例如在C++中,使用iostream的流操作进行I/O操作的时间就明显比使用stdio中的scanf来的要慢。这甚至可以消耗程序大部分的运行时间。
再或者对算法时间复杂度进行渐进分析的时候,我们舍去的系数与常量过大,导致最终算法运算规模并不小。这也是导致算法运行时间长的原因之一。(也就是所谓的卡常数)
那么这么说来的话,如何正确对待算法时间复杂度分析的结果就成了一个很值得探讨的问题了。
在这个问题中我们不妨把算法运行的时间设为$ f(x) $,其中的$ x $代表运算的数据规模。
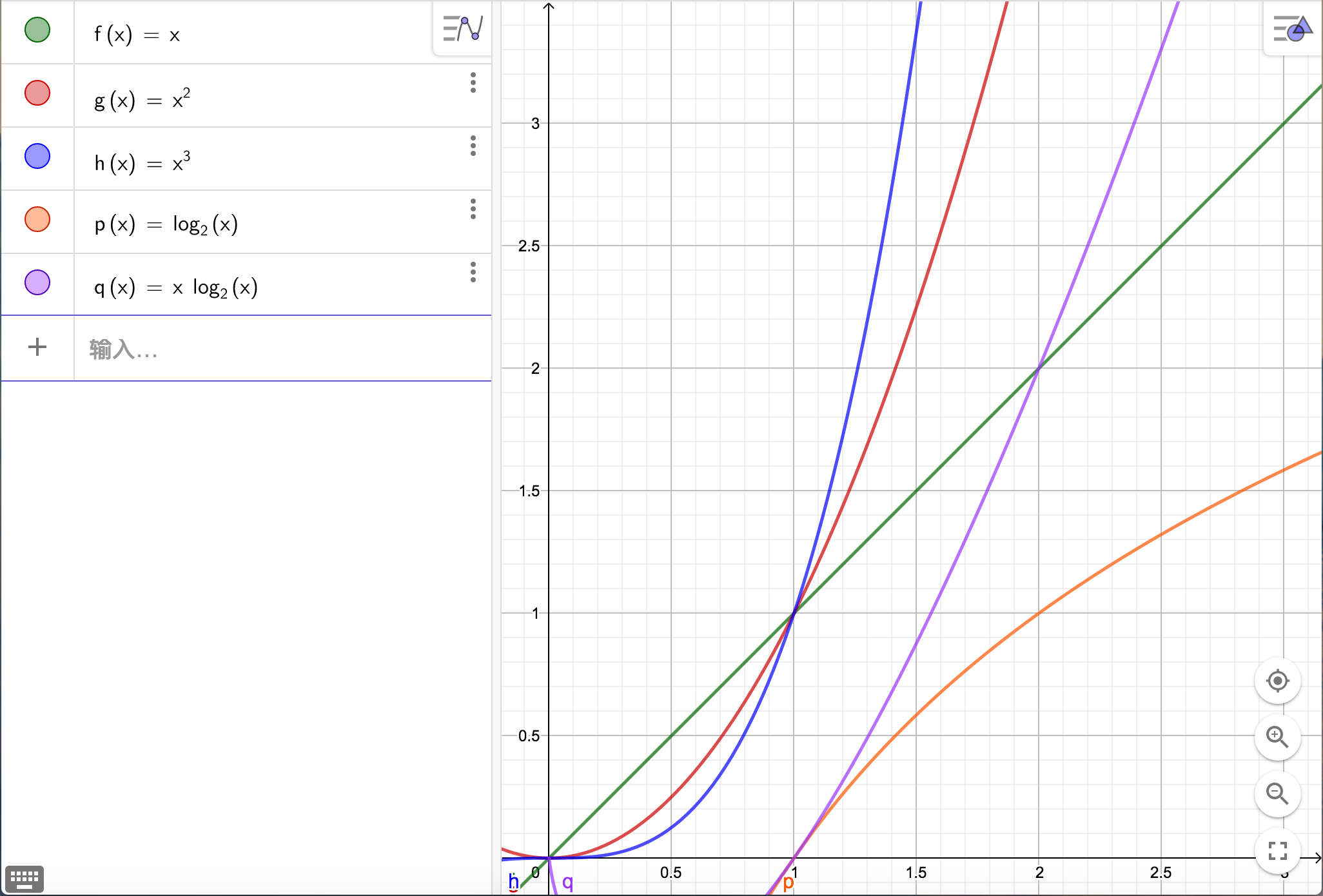
在上图中,我们绘制了一些常见的函数的图像,可以很直观地看出,函数值的增长变化是有很大差异的。
也就是$ O(1) 所以说,随着问题规模的扩大,时间复杂度越低的算法的优势越能体现的出来,而像阶乘级的算法就渐渐变得不可行了。 那么问题来了—— 答案是:我也不知道。 原因很简单,因为计算机硬件的差异过大,无法一概而论。(就比如你不能指望你的小笔记本电脑能和超级计算机跑某算法跑的一样快)。 我们在算法竞赛中一般会指定评测机的处理器,所以我们可以记住某些评测机的执行能力。 例如在NOIP中,评测机的大概能达到$ 10^8\to 10^9 $ 所以我们把数据规模带入算法时间复杂度中,如果大概落在这个区间就是可行的。 当然,我们每一次都严谨地去计算算法的时间复杂度也未免太过麻烦,这就需要我们套用我们渐进分析后的结果再结合由低次项带来的影响去判断算法的可行性。(这是一个需要累积经验的过程) --- ## 参考资料 * 算法导论
* 算法竞赛入门经典
